
엘리스 코딩의 ai 기본 과정을 수강하며 정리한 글입니다.
1장. 파이썬의 여러가지 모듈과 패키지
모듈을 불러오는 방법
1. from 모듈 (or 패키지) import 함수: 이 모듈에서 그 함수를 가져오겠다.
-> 함수() 꼴로 사용 가능
2. import 모듈: 이 모듈을 가져오겠다.
-> 모듈.함수() 꼴로 사용해야 함
2장. 데이터 핸들링을 위한 라이브러리 NumPy
NumPy?
- 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리 / 데이터 := 숫자 배열
- 반복문 없이 배열 처리 가능 (리스트에 비해 빠른 연산, 메모리 효율적 사용)
- list는 반복문 사용하는 배열이어서 오래걸림, 1차원의 배열
- numpy의 배열은 반복문 사용 안 해, n차원의 배열
- ndarray == n차원의 배열
# [0, 1, 2, 3, 4] 콤마로 구분 -> 리스트 -> class list 1차원
# [0 1 2 3 4] 공백으로 구분 -> 배열 -> class numpy.ndarray n차원
# numpy의 배열은 list()보다 빠른 연산, 효율적 메모리 사용 가능
# -> 빅데이터 분석 등에 널리쓰이는 매우 강력한 라이브러리!
np_arr = np.array(range(5))
배열의 기초 1. - 배열의 다양한 속성들
배열의 데이터 타입 dtype - 같은 데이터 타입만 저장 가능! (list와 다름)
배열(ndarray)의 속성: ndim(차원), shape(모양), size(크기), dtype(배열 요소의 자료형)
배열의 기초 2. - 2차원 배열
import numpy as np
# 1부터 15까지 들어있는 (3,5)짜리 배열을 만들자
matrix = np.array(range(1,16)
matrix.shape = 3,5
# matrix = np.array(1,16,1).reshape(3,5)
# matrix의 dtype을 str로 변경하여 출력하자
print(matrix.astype('str'))
Indexing & Slicing
Indexing: 인덱스로 값을 찾아냄 # arr[3]
Slicing: 인덱스의 값으로 배열의 일부분을 가져옴 (start ~ end-1) # arr[1:4]
Boolean indexing - true, false 여부 # arr[arr<3]
Fancy indexing (찾고 싶은 자리) - 인덱스에 어떤 값이 있는지? # arr[[1,3,5]] 배열의 1번째 3번째 5번째 자리에 있는 값은?
* 원하는 요소를 지정하고 싶다 <- 인덱싱과 슬라이싱 적절히 조합해서 사용 가능!
3장. 데이터 조작 및 분석을 위한 Pandas 기본
1. Series 데이터 (= Data + Index) <- 딕셔너리와 비슷
- values를 ndarray 형태로 가짐
- dtype 인자로 데이터 타입 지정 가능
- 인덱스 지정 가능, 인덱스로 접근 가능
import pandas as pd
data = pd.Series([1,2,3,4], dtype="float")
print(data.dtype) # float64 (원래 defalut는 int64)
data = pd.Series([1,2,3,4], index=['a', 'b', 'c', 'd']) # 시리즈 데이터 만드는 법
data['c'] = 5 # 인덱스로 접근해 요소 변경 할 수 있음
2. 데이터프레임
- 여러 개의 Series가 모여 행과 열을 이룬 데이터
- Dictionary 활용해서 DataFrame 생성 가능!
data = {
'name': ['minji', 'jieun', 'hanna', 'eric'],
'height': [169, 155, 175, 182],
'weight': [60, 50, 55, 75]
}
name = pd.DataFrame(data) # 딕셔너리 data로 DataFrame을 만듦
name = name.set_index('name')

3. 데이터 선택 및 변경하기
데이터 선택 - Indexing / Slicing
1) loc : 명시적 location
2) iloc : 암묵적
- loc
# 인덱싱
name.loc['minji'] # index가 minji인 것의 data를 구해라
# 슬라이싱
name.loc['jieun':'hanna', :'weight']
# 인덱스 컬럼
* 슬라이싱 할 때, 숫자) 1:3 하면 1부터 2까지이고, 문자) jieun:hanna하면 jieun부터 hanna까지 인가봄.
- iloc
구체적인 인덱스나 컬럼의 이름을 모를 때는 iloc를 사용.
.iloc : 파이썬 스타일의 정수 인덱스 인덱싱/슬라이싱 (암묵적인 순서 -> 값) ex. 최진사네 여섯 째,,
name.iloc[0]
name.iloc[1:3, :2]
# 인덱스는 1부터 3-1=2까지 불러오기
# 컬럼은 처음부터(0부터) 2-1=1까지 불러오기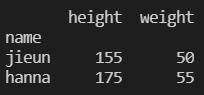
데이터 선택 - 컬럼 선택
: 컬럼명 활용하여 DataFrame에서 데이터 선택 가능
name['height'] - 컬럼
name[['height']] - 데이터 프레임
데이터 변경
1 - 데이터 추가/수정
1) 리스트로 추가
2) 딕셔너리로 추가
df = pd.DataFrame(columns = ['이름','나이','주소']) # 데이터프레임 생성
df.loc[0] = ['길동', '26', '서울'] # 리스트로 데이터 추가
df.loc[1] = {'이름':'철수', '나이':'25', '주소':'인천'} # 딕셔너리로 데이터 추가
df.loc[1, '이름'] = '영희' # 명시적 인덱스 활용하여 데이터 수정
2 - NaN 컬럼 추가
nan = not a number
df['전화번호'] = np.nan # 새로운 컬럼 추가 후 초기화
df.loc[0, '전화번호'] = '01012341234' # 명시적 인덱스 활용하여 데이터 수정
3 - 컬럼 삭제
DataFrame에서 컬럼 삭제 후 원본 변경
df.drop('전화번호', axis=1, inplace=True) # 컬럼 삭제axis = 1 : 열 방향
axis = 0 : 행 방향
inplace = True : 원본 변경
inplace = False : 원본 변경 X
데이터 선택
1 - 조건 활용
조건에 맞는 DataFrame 행 추출하기!! <- Masking 연산 / query 함수 활용
country[country['population'] < 10000] # masking 연산
country.query("population > 100000") # query 함수
4장. 데이터 조작 및 분석을 위한 Pandas 심화
1. 데이터프레임 정렬하기
- 인덱스 값 기준
df = df.sort_index(axis=0) # 행 기준, 오름차순 디폴트
df.sourt_index(axis=2, ascending=False) # 열 기준(컬럼), 내림차순 정렬
- 컬럼 값 기준
df.sort_values('col1', ascending=True) # col1 컬럼 기준 정렬, 오름차순 디폴트
df.sourt_values('col1', ascending=False) # 내림차순 정렬
- 한 번에
df.sort_values(['col2', 'col1'], ascending = [True, False])
# col2 컬럼 기준 오름차순 정렬 후 col1 컬럼 기준 내림차순
# col2 먼저 !!
2. 데이터프레임 분석용 함수
- count - int형
- max, min (default: 열 기준, NaN값 제외) - float형
- sum, mean(평균) - float형
axis = 1 (행 기준!, 디폴트 아님)
skipna = False (NaN값 포함)
Q. math 컬럼의 결측값을 해당 컬럼의 최솟값으로 대체하고 df를 출력해라. (fillna() 사용)
# 컬럼의 최솟값으로 NaN값 대체
math_min = df['math'].min()
df['math'] = df['math'].fillna(math_min)
print(df, "\n")
# 각 컬럼별 평균
col_avg = None
print(col_avg, "\n")
3. 그룹으로 묶기 - group by
- aggregate
df.groupby('key').aggregate(['min', np.median, max]) #1번
df.groupby('key').aggregate({'data1:'min', 'data2':np.sum}) #2번
Q. 그룹으로 묶기
import numpy as np
import pandas as pd
df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': [0, 1, 2, 3, 4, 5],
'data2': [4, 4, 6, 0, 6, 1]
})
print("DataFrame:")
print(df, "\n")
# aggregate를 이용하여 요약 통계량을 산출하자.
# 데이터 프레임을 'key' 칼럼으로 묶고, data1과 data2 각각의 최솟값, 중앙값, 최댓값을 출력해라.
print(df.groupby('key').aggregate([min, np.median, max]))
# 데이터 프레임을 'key' 칼럼으로 묶고, data1의 최솟값, data2의 합계를 출력해라.
print(df.groupby('key').aggregate({'data1':min, 'data2':sum}))
5장. Matplotlib 데이터 시각화
Matplotlib 그래프
# Line plot
fig, ax = plt.subplots()
x = np.arange(15) # 0~14
y = x ** 2
ax.plot(
x, y,
linestyle=":",
marker="*"
color="#524FA1"
)
* 엘리스 코딩의 2021 AI 온라인 실무 기본 교육 과정 내용을 바탕으로 작성했습니다.